State, Local, and Tribal Action Plans and Assessments

Many subnational climate change decisions are explored and enacted through climate action plans, vulnerability assessments, or a combination of the two. Developed by state, local, and tribal governments, the format and focus of these documents can vary widely. Planners within these jurisdictions, or their consultants, can draw on climate information and decision-support resources to inform these plans and assessments.
As publicly available documents, plans and assessments suggest the types and sources of climate information, if any, communities actually use. As more jurisdictions and sovereign tribal territories consider and reconsider climate impacts and responses, these documents offer a glimpse into patterns of climate information use over time and geography. However, new tools are required to analyze the growing body of climate plans and vulnerability assessments. In this investigation, we explored how natural language processing (NLP) could assist researchers in making sense of patterns in climate information use.
Investigation overview
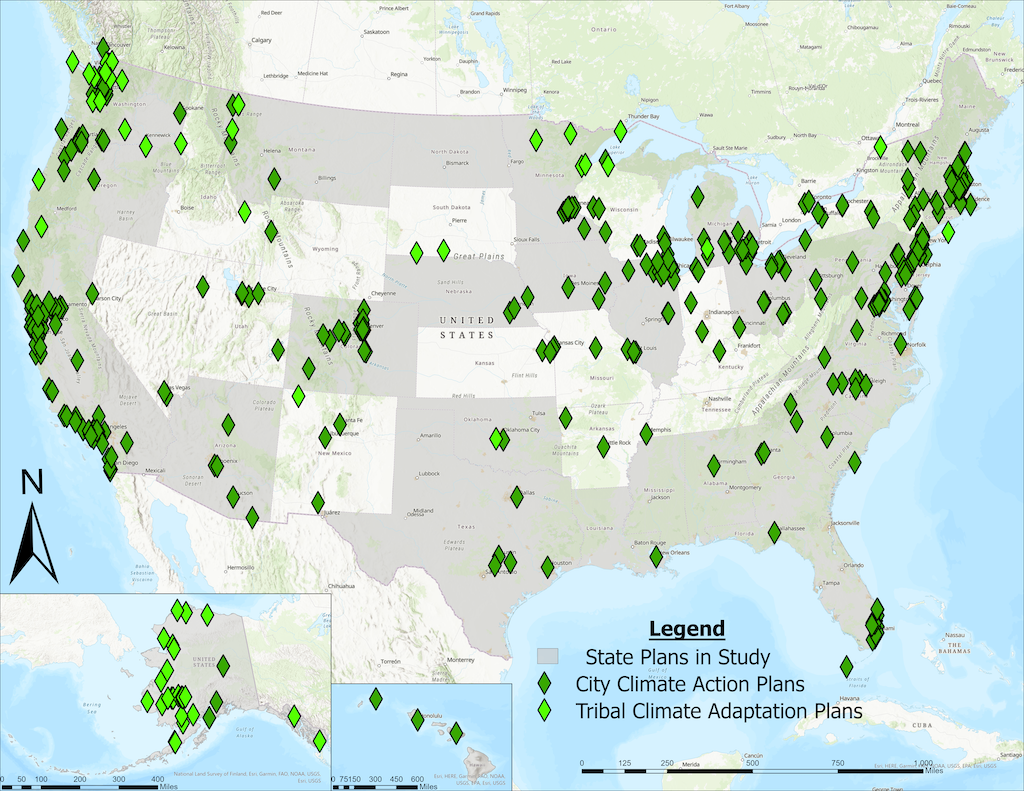
This ongoing investigation is training a large language model (LLM)-based tool to perform a multi-label classification task (a form of NLP) on a large corpus of sentences from plans and assessment texts. To detect patterns in climate information use. We compiled a large sample of existing climate change plans and assessments from state, local, and tribal websites (n=366) and processed these documents into machine-readable texts. Using 115 “fingerprints,” or keywords, associated with potential climate information use, we filtered the total body of text down to 187,364 sentences for focused LLM development.
To train the model, a sample of 1,000 sentences from the filtered set was provided to study team members with content expertise in climate information. Study team members evaluated each sentence, classifying each with up to six labels (i.e., attributes) of relevance to this study: 1) observations (ground- or satellite-based); 2) projections (model-based forecasts and scenarios); 3) integrated assessment and impacts; 4) decision-support tools; 5) descriptions of how climate information decision support is used; and 6) evidence of NASA-specific resources cited.
As of January 2025, we have achieved satisfactory predictive skill for two of these six labels and are in the process of sampling and tagging an additional ~1,000 sentences for further training. When model improvement tasks are complete, we expect to be able to associate predictions with attributes of plans, such as plan type, location, population size, and year of publication to further study spatial, temporal, and socioeconomic drivers of climate information use.
Preliminary Findings
This investigation and corresponding paper are still in progress. Additional findings and details will be added as they near completion.
Climate change information and decision support are being accessed and utilized.
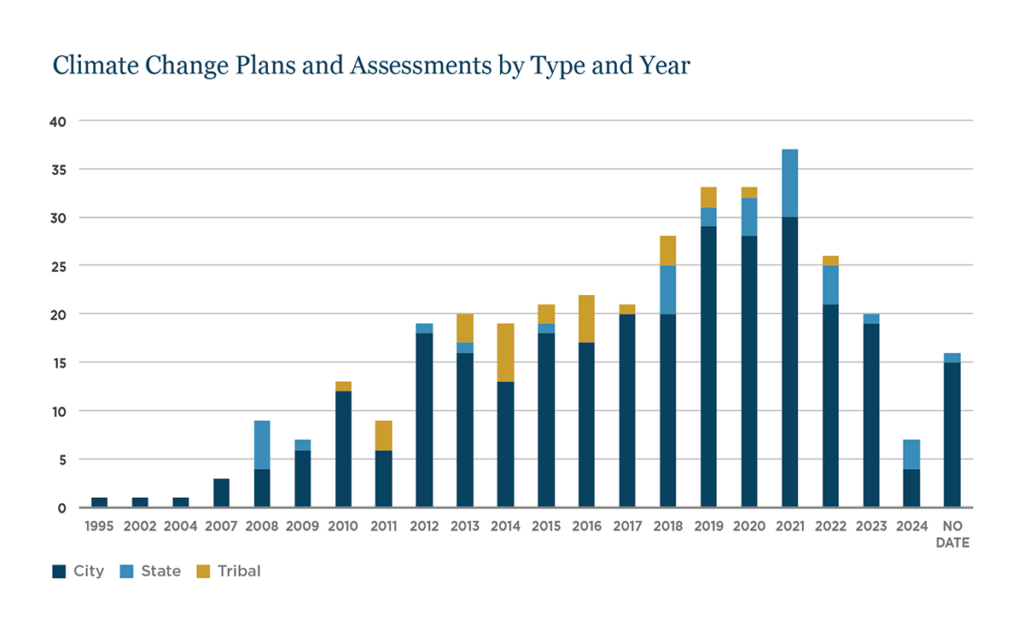
The resulting collection of plan and assessment documents (see Figures 1 for map and 2 for time series), along with the model training process, is already providing new insight into the extent and variety of climate planning efforts and the means by which they are informed. Communities are accessing and using climate information and decision support tools in myriad ways, from documenting the extent of historical climate changes in their locality to stating projected ranges of future change that may be anticipated to linking climate-specific changes with impacts and potential solutions.
Promising methodology
Building on recent related work that used unsupervised topic modeling on resilience planning documents, this investigation’s approach employs supervised learning with models trained on expert-curated annotations. Once model training for this stage of the project is completed, we will be able to evaluate the models’ classification skill on the larger amounts of data not reviewed by humans. If skillful, further training could be completed on other labels of interest to researchers, funders, or practitioners, and additional documents could be added to the corpus. In addition, we currently believe that this approach may provide a more cost-effective and energy-efficient approach than utilizing commercially available generative LLMs such as ChatGPT or Claude.
Opportunities to explore new questions
While an initial motivation for this study was to add descriptive power to mapping the landscape of climate change decision support (i.e., providing evidence for what information is being used), combining skillful analysis of plans with data about the communities that prepared them may allow for more inferential studies of the drivers of climate information use. For example, future stages of this study could explore how community size, location, and socioeconomic factors lead to different kinds or sources of climate information use. This study may also help us further explore the questions around climate information navigation and quality control raised in our investigation on Online Climate Information Resources and Portals.
For more information on this investigation, contact jamesa@agci.org.



